|
The Precision Farming Primer |
|
|
|

Smart Farmers and Dumb Maps — identifies differences between descriptive and
prescriptive mapping
GIS Quality
Data — describes a field's
geographic patterns as an organized set
of numbers
Four Basic Steps in Precision
Farming — describes the basic steps of
the precision
farming process
Putting
Yield in Its Place — discusses differences in
mapping yield as discrete points
or continuous surfaces
Putting
Yield in Its Proper Place — describes the major factors affecting geo-referencing
of "raw" yield data
Connecting
the Dots — discusses the implications of
point, swath, and grid formats for mapping yield data
Is
Precision Farming Accurate? — investigates differences between precision and
accuracy
Resolving
Yield Mapping Issues —
describes the "accuracy advantage" of grid formatted data
(Back to the Table of Contents)
______________________________
Smart Farmers and Dumb
Maps (return to top of Topic
1)
We have been mapping for more than 8,000 years and farming even longer. So what makes the merger of maps and fields in precision farming so radically new and confusing? The precision farming revolution involves a new perspective of mapped data from one of description of the precise placement of physical features to one of prescription of appropriate actions based on spatial analysis. This transition involves extending the familiar paper map composed of inked lines and shadings to the somewhat intimidating digital map world of organized sets of numbers. In terms of mapped data it involves recognition of the differences between cartographic and geographic information systems (GIS) data quality. Cartographic quality uses the stored numbers simply as surrogates for pen colors of traditional map features. Computer-assisted design (CAD) drawings and graphical representations of maps use this approach and often are referred to as "dumb maps" because they merely automate descriptive mapping. The objective of these systems is drafting traditional map products, not map analysis for management action. Cartographic quality numbers also can serve as an index to feature attributes stored in a database enabling rapid access to database information and map displays of the data. The GIS quality numbers, on the other hand, respect all of the "map-ematical" rights, privileges and responsibilities needed for spatial statistics, analysis and modeling required for the prescriptive maps in precision farming.
GIS Quality Data (return to top of Topic
1)
Cartographic quality data simply use the
stored numbers as surrogates for pen colors in drafting traditional map
features and "geo-query" of the data. The numbers in GIS quality
data, on the other hand, respect all of the map-ematical rights, privileges and
responsibilities you fondly recall from high school math. At the heart of
precision farming is the recognition that maps are organized sets of numbers
poised for analysis.
Consider the derivation of a map of soil
phosphorous levels from a set of soil samples depicted in figure 1.1.
Inset (a) shows the level of phosphorous (P) for 16 samples taken from a
field. The normalized values range from almost 0 to 87, with the higher
levels depicted as the taller points. Note the lowest levels occur on the
left side of the field. A "first-order" estimate of the spatial
distribution of the data in inset (b) assigns the P-level of the closest sample
for each location throughout the field (discrete sample points to continuous
map surface). In techy terms the blocks are called Thiessen polygons with sharp boundaries formed by the perpendicular
bisectors among neighboring samples.
|
|
|
Fig. 1.1. Deriving geographic distributions. |
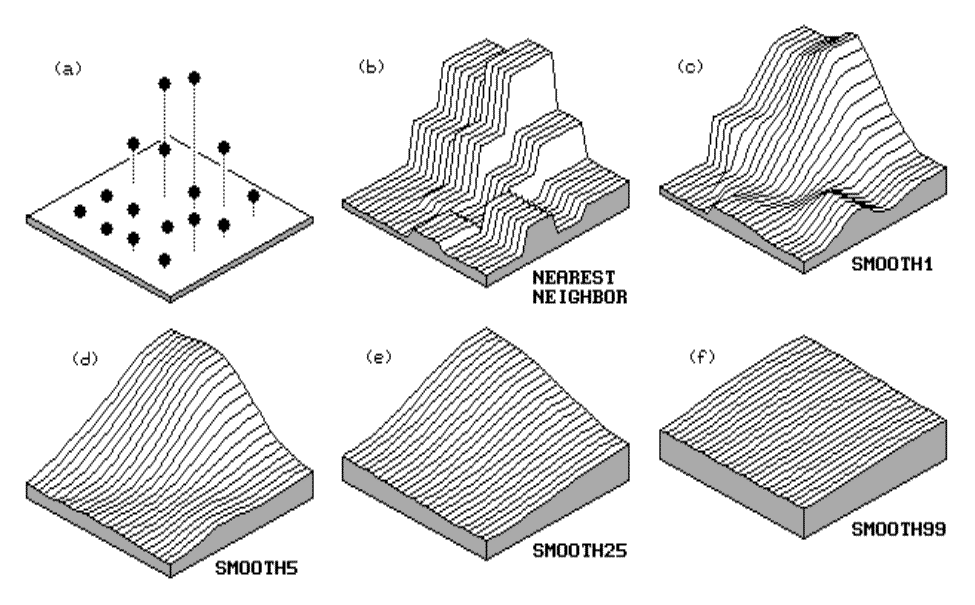
Inset (c) in the figure was derived by moving
a smoothing window around the nearest-neighbor
surface. When the window is centered near one of the sharp boundaries, it
has a mixture of big and small values, resulting in an average somewhere in
between—a whack off the top and a fill-in at the bottom. The remaining
insets (d) through (f) continue to smooth the phosphorous surface.
Eventually the surface will be completely eroded to a flat plane in inset (f)
that approximates the average of the whole field—the ultimate in spatial
aggregation.
That brings us to the crux of precision
farming and variable
rate technology (VRT). In the
past you set the fertilizer rate for the average level of P in the field and
let ‘er rip—everywhere the same based on the field average. But a lot of
information locked in the field samples was thrown away. In precision farming/VRT
the onboard computer gets a reading from the GPS unit, positions itself on the
phosphorous surface, checks the P value for that part of the field, then sets
the rate so just the right amount is applied. As the tractor moves
through the field, the rate is continuously varied based on the spatial
calculations. How well the system works has a great deal to do with the
data quality and the spatial stat/math used in the.
Four Basic Steps in
Precision Farming (return to top of Topic
1)
In the introduction
we noted three basic technologies driving precision farming:
- global positioning systems (GPS) for positioning,
- geographic information systems (GIS) for analyses, and
- intelligent devices and implements (IDI)¾ such as yield monitors and variable-rate fertilizer rigs¾ for "on-the-fly" data collection and variable-rate control of field inputs.
Now that the basic elements are in place four
basic processing steps in precision farming tie it all together:
- continuous data logging
- point sampling
- mapped data analysis
- spatial modeling
The data logging and point sampling
steps provide the base maps of yield and field conditions, such as soil
properties and nutrients. The mapped data analysis step uses the
computer to establish the relationships between the output (yield map) and the inputs (soil properties and nutrient
maps). This step is analogous to the ag researcher’s derivation of the
familiar crop production functions published in texts and reports. The
main difference is that the analysis generates a production curve for your own
backyard—not for a research field 70 miles away on a different soil and using
different varieties. The spatial modeling step uses your tailored
"backyard" relationships to determine appropriate management actions
and, as Fran Pierce of Michigan State puts it, the "if <condition>
then <action>" guidance a farmer needs. The difference from
traditional research and guidance is that precision farming’s recommendations
respond to the unique conditions and variability within your field and is
reported in the form of a map. Admittedly, this process might seem a bit
overwhelming at first¾ and more appropriate for a "techno-farmer"¾ but it could be heralding the next revolution in agriculture.
Putting Yield in Its Place (return to top of Topic
1)
The yield monitoring step in the
above-mentioned process is rapidly becoming commonplace and seems to be fading
as high tech talk at the coffee shop. The new buzz is about yield mapping, which hooks a yield monitor’s output to a
computer. The GPS "stamps" these data with earth coordinates,
thereby enabling the computer to map them. There has been a fair amount
of discussion about the accuracy of the GPS stamp, but less discussion about
the process and accuracy involved in generating a yield map—the art and science
of creating "pretty maps." The data logging of yield results in
thousands of point
measurements over a field.
Some mapping systems simply place a small colored dot at each location, with
the color indicating relative yield. The assembled mass of dots forms a point map with color patterns tracking the differences in yield
throughout a field. Although point mapping generates acceptable map
images, it doesn’t provide the consistent data structure needed for map
analysis. An alternative approach uses a rectangular grid to summarize
yield for a continuous
map by averaging the measurements
falling in each grid cell (see fig. 1.2). Many of these systems use
smoothing windows that weight-average numerous points around a cell as a means
to remove measurement
noise and get a better generalization
of the data’s spatial distribution. Also, the summary for each cell
provides statistics about localized yield variation, such as a standard deviation map, which directs attention to areas with highly
variable yields—salt-and-pepper patterns of high and low yields. More
importantly, the grid forms a consistent structure for relating different maps,
such as the percentage of change in yield between two years or the correlation
among yield and soil nutrient maps (mapped data analysis).
However, there are several technical issues that, if ignored, turn the science
of yield mapping into a large part art. These issues will be addressed
throughout the book.
Note:A short paper by Tom Doerge
discussing the benefits of yield monitoring and mapping is available in
appendix A, part 1, "Yield
Mapping Considerations, Yield
Monitors Create On- and Off-Farm Profit Opportunities."
Putting Yield in Its Proper Place (return to top of Topic 1)
Precision farming presumes you have good data
to analyze. Before we forge ahead, it might be prudent to investigate the
issues that can turn good data bad, specifically, the precise placement of yield measurements.
|
|
|
Fig. 1-2. Aggregating yield into grid cells. |
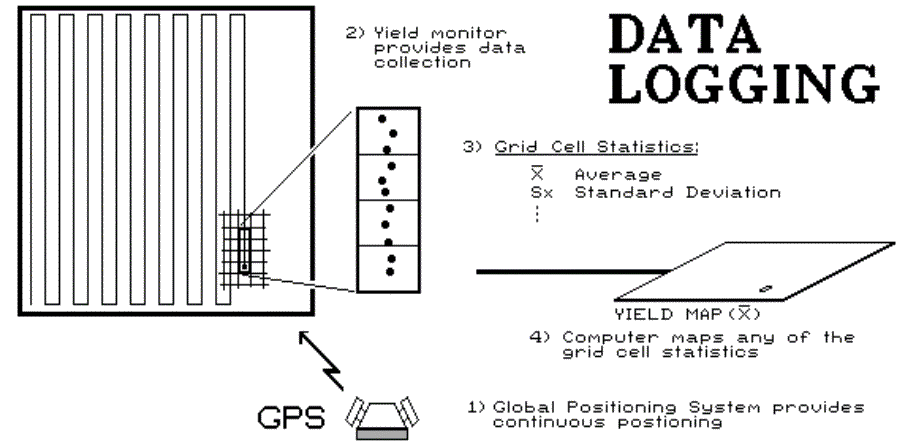
Your GPS may be accurate to a meter, but does
that same precision hold for the yield data? Three factors beyond the GPS
signal influence the precise placement of yield measurements: 1) antenna
offset. 2) mass flow adjustment, and 3) synchronization of computer
clocks.
Antenna offset is the easiest to deal with
because it simply adjusts for the fixed distance from the harvesting point to
where you anchored the antenna. Simply plug in the offset and correct for
the point of harvest¼ sort of. That's the current point (inset T2 in
fig. 1.3), but the material at the yield sensor at that moment was collected
somewhere further back (inset T1). A simple fixed distance offset to the
yield monitor won't do, as the path of the material doesn't conform to simple
geography.
|
|
|
Fig, 1.3. Mass flow delay repositions yield measurements. |
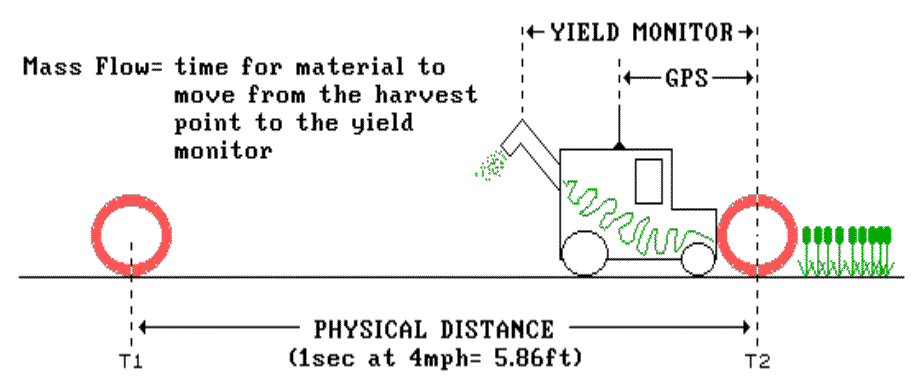
Several things contribute to the dynamics of
mass flow through the harvester, and ultimately the calculation of the physical
distance needed to put the yield measurement in its proper place. First,
the mechanical design of the harvester follows a contorted internal path to the
yield monitor. The twisted path coupled with the speed of the conveyor
belts results in a processing time delay as the material moves through the
system.
Under constant conditions the delay can be
measured and the physical distance calculated by multiplying the standard delay
by the harvester's speed. For example, a delay of 16 seconds at 4 mph
repositions the current yield measurement about 70 feet behind—kind of like a
trolling a lure behind a boat. However, things aren't that simple.
What happens on turns? Harvesting pauses, speed changes, the line bends,
the processing path clears out, then harvesting resumes; all of which makes
repositioning the yield measurement a lot tougher.
Even on the straight-away, things are a lot
more complex than simply trolling for data. There is a myriad of
muddling factors. Consider moving down a slope in a dense part of the
field¾ material accumulates so the processing delay is
increased to 19 seconds and the speed is cut back to 3 mph to handle the
flow. The physical distance under these conditions extends to nearly 84
feet (4.4 ft./sec. * 19 sec.).
The final issue involves synchronization
of computer clocks. Like a metronome, the GPS and yield monitors are
sampled at a given downbeat (e.g., each second). However, communications
interference across the I/O bus in the hardware can
stall things, particularly when recording conflicts with writing out data
buffers or screen display updates. Like a lousy dancer, a dropped
downbeat can really step on your toes.
All this seems to make an accurate yield map
beyond reach and precision farming a pipe-dream. Not true; what it should
do is alert you that "dumb maps" simply put a yield measurement at
its initial GPS position. It should also arm you with some serious
questions to look into about how "smart" your mapping software
actually is. Many of these issues or questions are presented in appendix
C, "Checklist for Yield
Mapping Software."
Note:A short paper by Neil Havemale
discussing several factors affecting spatial accuracy in yield mapping is
available in appendix A, part 1, "Yield
Mapping Considerations, Yield
Mapping Sparks Precision Farming Success."
Connecting the Dots (return to top of Topic
1)
The sage advice of "what seems simple
ain’t" certainly holds for precision farming. The precise placement
of GPS yield records isn’t simply reflected in the accuracy of a GPS unit.
A mass flow offset is required to place the measurement somewhere behind
the instantaneous GPS location. The offset accounts for the time it takes
for plant material to move from the harvest point to the yield monitor, and its
calculation involves a complex interaction between mechanical design and amount
of material flow. The delay multiplied by the intervening speed
calculates the offset, which is used to reposition a yield record. The
ability of yield mapping software to account for mass flow dynamics is the key
to precise placement of yield measurements.
However, the geographic treatise of the
precisely placed points determines, to a large extent, what you can do with the
data. Figure 1.4 illustrates how yield options can be calculated. A
point map, inset (a), is the simplest rendering of yield data. It uses a
fixed symbol, such as a dot centered on a point’s x,y coordinates, which
is assigned a color corresponding to an interval of yield such as dark green
for 150 to 200 bushels of corn. When viewed, groups of similarly colored
dots form patterns of yield variation. The display is visually effective
but lacks the geographic structuring needed for data analysis. In the
computer, the coordinates and yield values simply form a long list of
independent numbers—your eye and brain assembles the data into patterns of
neighboring points.
|
|
|
Fig. 1.4. Basic types of yield options. |
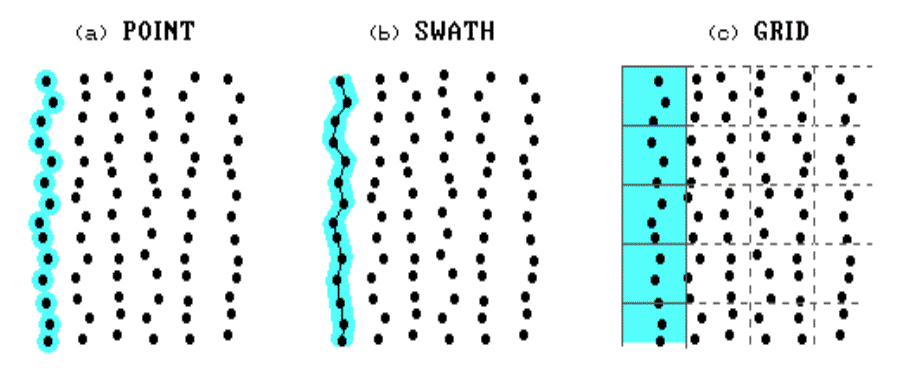
A swath map, inset
(b), provides a bit more data organization by linking points along a
harvester’s path. The swath can be sequential pairs of points, but often
is represented as a mathematical
vector (line segment), plotted as a
rectangle with a width of the harvester’s header and a length of a set number
of consecutive points. The color fill of the rectangle (termed a swath
element) is determined as the average of the yield points it
contains. Swath elements can be plotted to align with the actual GPS
coordinates forming a jagged path, or they can be "forced" to the
straight lines characterizing adjoining harvester paths. The advantage of
swaths over points is that the computer "sees" more of the
relationships in the data—sequencing, length, alignment, and data smoothing.
However, both data structures are too limited for data analysis as they are
based on irregular geographic units (points and rectangles) of varying sizes
and placement.
A grid map, inset
(c), on the other hand, uses a regular grid to statistically summarize the
data. Like the daily or weekly reports of commodity prices, averages are
useful in determining trends from the volatility of moment-by-moment price
fluctuations. In addition to a better representation of field trends, a
regular grid provides the geographic consistency the computer needs to analyze
data patterns within and among maps. Since the size and spacing of grid
elements are consistent, the computer can easily locate neighboring cells for intramap
analysis, such as average yield for different portions of a field. More
importantly, the consistent partitioning into grid cells provides the structure
for intermap analysis, such as relating a yield map to soil nutrient
maps. Generally speaking, point and swath maps support graphical analysis (visualization), and grid maps support data analysis (map-ematical). Both perspectives are needed.
Is Precision Farming Accurate? (return to top of Topic
1)
What’s the difference between precision and
accuracy? Is it merely semantics? Is a precise device always
accurate? Or can precise measurements still produce inaccurate data?
Precision refers to the "exactness of a measurement";
accuracy refers to its "correctness." Precision is
dependent upon
- measurement scale (e.g., eighth-of-an-inch tic marks of a first-grader’s
- straightedge versus thousands-of-a-foot marks on an engineer’s rule) and
- measurement procedure (e.g., sloppy versus careful alignment).
Precision is focused on the repeatability of measurements; accuracy
seeks appropriate representation of a characteristic or condition.
One source of imprecision is termed random
error. Sometimes measurements are more than and sometimes they’re
less than without any discernible pattern. In most instances, this
"noise" is easily remedied—simply take a bunch of readings and
average them. However it’s impossible to repeatedly harvest and measure
the same spot in a field so we assume random error is minimal in our yield
monitors and choose to ignore it.
Another situation is termed biased error.
Your bathroom scale might repeat time after time that you weight 201 pounds,
but you know it’s always 10 pounds over so your weight is actually only
191. In precision farming you might have a precise yield monitor that
repeatedly records differences within a bushel, but always 10 over.
That’s easy to remedy—measure known amounts and calculate a calibration factor
(subtract 10).
Things get a bit tougher if the bias changes
with the level of measurements; say at least 10 more for high readings to 10 or
less for low ones. Now you have to develop a calibration function whose
adjustments change as the yield values change. Even more insidious is
biased error that results from a complex interaction of several factors, such
as the dynamic mass flow adjustments of yield discussed earlier (see "Putting
Yield in Its Proper Place").
So what sort of error does a weigh-wagon calibration address? If the actual weight is 10 percent
more than the yield monitor estimate (spatial integral
for you techy-types) most folks simply adjust each yield record by 10
percent. Sure, the mathematics works as both the weigh-wagon and monitor
values for the area are forced to be the same. But does a spatially
aggregated benchmark make sense as a spatial calibration factor? Actually
it doesn’t make any difference—spatially, that is. Every point simply is
increased by 10 percent so the pattern (relative yield)
hasn’t changed. What’s needed is research into the nature of yield map
errors and effective calibration functions.
If "appropriate adjustment" of
imprecise data is one way to make measurements more accurate (measurement accuracy), another way is to aggregate the data to
characterize a larger unit (feature accuracy). For
example, politicians do this all the time. They aggregate data on
individuals into statistics about groups of people that best represent general
characteristics of voters, then tailor their spiel to the nonexistent typical
person representing each group. That’s sort of what a grid map does to
yield records—it summarizes them into spatial groups (grid cells). As in
most statistical applications, the summary tends to enhance trends by dampening
individual fluctuations. It recognizes that site-specific management
doesn’t operate at the individual plant level, but somewhere between that and
whole-field management. What’s needed is a better understanding about how
best to define the aggregation unit (grid cell) and determine the best mix of
management actions (fertilizer blend, seeding rate, variety selection, etc.)
for each of them. Bet you never knew you had so much in common with a
politician.
Resolving Yield Mapping Issues (return to top of Topic
1)
There are two main advantages to this
approach:
- It provides consistent geographic referencing among various mapped data layers.
- It smoothes out measurement noise while reporting statistics on localized yield variation.
However, there are a few of technical issues
that need to be considered. First, the gridding resolution (cell
size) can greatly affect the calculations. Insets (a) and (b) in figure
1.5 depict two gridding resolutions. Note that the number of points falling
in the cells is significantly different between the two resolutions; hence, the
average yield reported will most certainly differ. If the grid pattern is
too large, some of the information in the data will be lost (averaged-over).
If it is too small, undue credence might be attached to differences
arising simply from measurement and positioning errors.
|
|
|
Fig. 1.5. Summarizing yield measurements. |
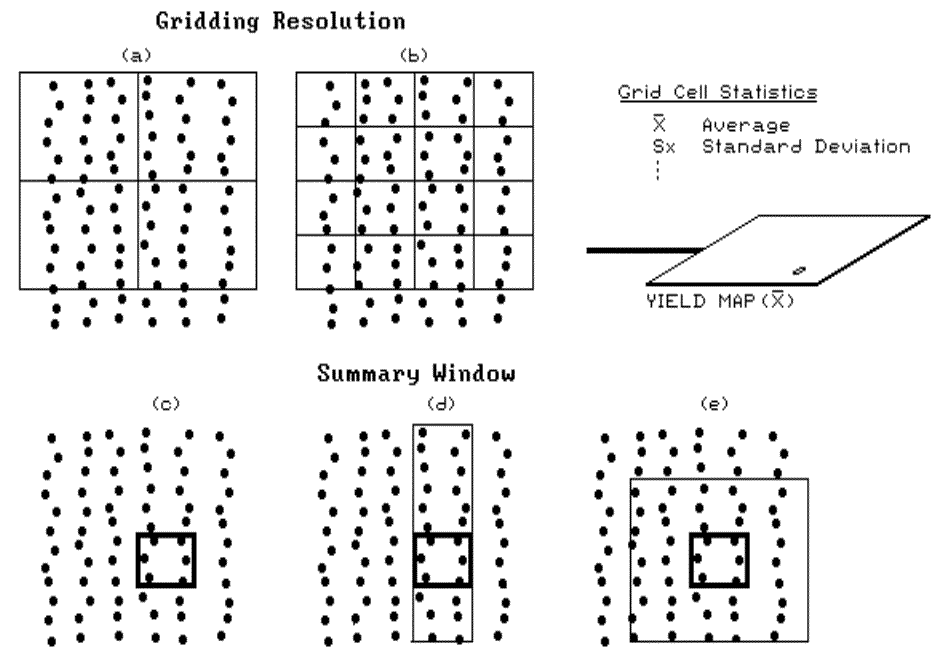
Other technical issues involve the definition
of the summary window and the summary procedure used. Insets (c), (d) and
(e) show three different summary window designs—single-cell, inline filter and
nearest-neighbors summary. The single-cell design uses only those
measurements that actually fall within a cell for the summary
calculations. The inline design uses the direction of travel to
"filter" surrounding data. It can help in smoothing out
measurement errors resulting from the "coughs and spits" due to
uneven grain flows through a combine. The technique is analogous to moving averages routinely used in analyzing times series data, such
as commodity prices or the stock market. Both the single and inline
techniques can be used for "on-the-fly" data compression—simply keep
the summary statistics and discard the pile of raw measurements.
The nearest-neighbors technique
involves the post-processing of the raw data. It moves a window around
the field sequentially centered on each grid cell. At each stop, it
calculates a summary for the points falling within the window and assigns that
value to that grid cell. In addition to window design, the summary procedure can vary—such as simple or weighted averaging.
For example, a distance-weighted average is influenced more by nearby
measurements than those that are farther away.
OK, where does all this leave us? It
should instill a healthy skepticism when viewing a yield map because different
approaches or different systems can create radically different looking
"pretty maps" from the same data set.