Column Supplement for
Linking Data and Geographic Distributions
Beyond Mapping column, GIS World Magazine, June, 1998.
The following discussions are from the "Inside the GIS Toolbox" column in
@gInnovator and contain some additional thoughts on linking Data Space and Geographic
Space. @gInnovator is published by Successful Farming, Meredith Publishing, 1716 Locus
Street, LS 345, Des Moines, Iowa, 50309-3023, phone/fax 800-808-2828. Information on
@gInnovator and applications of GIS technology in agriculture can be found on the Internet
at http://www.agriculture.com/technology
.
Sticks and Stones (06/97
– ag/INNOVATOR)
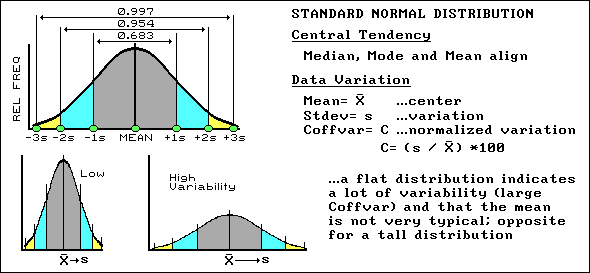 The last article described some basic concepts in
statistics: minimum, maximum, median, mode and mean. The discussion noted
that these "metrics" are used to reduce thousands of measurements (such as those
from a yield monitor) to their typical value, termed the central tendency. Recall that the
ideal, "normally distributed" data forms a bell-shaped curve with the min/max at
either end, and the median, mode and mean aligning at the halfway point (see figure). Now
let’s turn our attention to the tough stuff… characterizing the data variation
about the mean. As before, the concepts are easy. It’s the terminology and elegant
theory that’s intimidating, so keep in mind that "sticks and stones may break
your bones, but words will never hurt you." To characterize the variation in a set of
data we must confront the concept of a standard deviation (Stdev). The
standard deviation describes the dispersion or spread of the data around the mean.
It’s a consistent measure of the variation in the data, as one standard deviation on
either side of the mean "captures" slightly more than two-thirds of the data (1
Stdev= .683 of the area under the curve). Approximately 95% of all the measurements are
included within the interval +2 to -2 standard deviations, and more than 99% are covered
by three standard deviations (see figure). The larger the standard deviation, the more
variable is the data, therefore the less useful is the mean as being "typical"
for an area. In precision farming, a small standard deviation in yield tells you there
isn’t much variation in the field, and using whole field averages in decision-making
might be OK. However, a large standard deviation indicates a lot of variability and using
simple averages might miss the mark more than it hits it. So what determines whether the
standard deviation is large or small? That’s the role of the coefficient of
variation (Coffvar). This semantically-challenging mouthful simply
"normalizes" the variation in the data by expressing the standard deviation as a
percent of the mean—if it is lot, say over 25%, then there is a lot of variation and
the mean is a really mean (poor) estimator of what’s happening in the field. Another
advantage of using the Coffvar is that it allows you to compare the variation among
different data sets. For example, if you had the field in soybeans last year and you
wanted to compare its "relative" yield to this year’s corn, you can’t
use the absolute measures. A standard deviation of 15 with an average yield of 150 bushels
of corn isn’t much variation (15/150*100= 10%), but it’s a lot for an average of
35 bushels of soybeans (15/35*100= 42%). Next time we will go into more detail about
"normalization" and investigate what to do if the data isn’t
"normal" (skewed and bi-modal distributions). Keep on plowing
‘til then.
The last article described some basic concepts in
statistics: minimum, maximum, median, mode and mean. The discussion noted
that these "metrics" are used to reduce thousands of measurements (such as those
from a yield monitor) to their typical value, termed the central tendency. Recall that the
ideal, "normally distributed" data forms a bell-shaped curve with the min/max at
either end, and the median, mode and mean aligning at the halfway point (see figure). Now
let’s turn our attention to the tough stuff… characterizing the data variation
about the mean. As before, the concepts are easy. It’s the terminology and elegant
theory that’s intimidating, so keep in mind that "sticks and stones may break
your bones, but words will never hurt you." To characterize the variation in a set of
data we must confront the concept of a standard deviation (Stdev). The
standard deviation describes the dispersion or spread of the data around the mean.
It’s a consistent measure of the variation in the data, as one standard deviation on
either side of the mean "captures" slightly more than two-thirds of the data (1
Stdev= .683 of the area under the curve). Approximately 95% of all the measurements are
included within the interval +2 to -2 standard deviations, and more than 99% are covered
by three standard deviations (see figure). The larger the standard deviation, the more
variable is the data, therefore the less useful is the mean as being "typical"
for an area. In precision farming, a small standard deviation in yield tells you there
isn’t much variation in the field, and using whole field averages in decision-making
might be OK. However, a large standard deviation indicates a lot of variability and using
simple averages might miss the mark more than it hits it. So what determines whether the
standard deviation is large or small? That’s the role of the coefficient of
variation (Coffvar). This semantically-challenging mouthful simply
"normalizes" the variation in the data by expressing the standard deviation as a
percent of the mean—if it is lot, say over 25%, then there is a lot of variation and
the mean is a really mean (poor) estimator of what’s happening in the field. Another
advantage of using the Coffvar is that it allows you to compare the variation among
different data sets. For example, if you had the field in soybeans last year and you
wanted to compare its "relative" yield to this year’s corn, you can’t
use the absolute measures. A standard deviation of 15 with an average yield of 150 bushels
of corn isn’t much variation (15/150*100= 10%), but it’s a lot for an average of
35 bushels of soybeans (15/35*100= 42%). Next time we will go into more detail about
"normalization" and investigate what to do if the data isn’t
"normal" (skewed and bi-modal distributions). Keep on plowing
‘til then.
Typifying Atypical Data (07/97 – ag/INNOVATOR)
 Like most things, not all data sets are
ideal… in fact most are a bit quirky. Armed with this revelation you should be
squeamish about simply lying two maps side by side and jumping to conclusions about their
comparison. The similarities and differences might be just inconsistencies in generalizing
the maps (see Inside the GIS Toolbox, January and February, 1997). There are other
ways, however, to miss-interpret the comparison based on the data’s
characteristics—failure to normalize and non-normal distributions. Normalization
is just a fancy word for standardizing the data by introducing a common index. The
simplest index uses a common goal, such as 300 bushels of corn, and expresses actual
measurements from different years or neighboring fields as a percentage of the target.
This approach is similar to a financial analyst’s use of discounting to a "base
year" when comparing relative costs of living.
Like most things, not all data sets are
ideal… in fact most are a bit quirky. Armed with this revelation you should be
squeamish about simply lying two maps side by side and jumping to conclusions about their
comparison. The similarities and differences might be just inconsistencies in generalizing
the maps (see Inside the GIS Toolbox, January and February, 1997). There are other
ways, however, to miss-interpret the comparison based on the data’s
characteristics—failure to normalize and non-normal distributions. Normalization
is just a fancy word for standardizing the data by introducing a common index. The
simplest index uses a common goal, such as 300 bushels of corn, and expresses actual
measurements from different years or neighboring fields as a percentage of the target.
This approach is similar to a financial analyst’s use of discounting to a "base
year" when comparing relative costs of living.
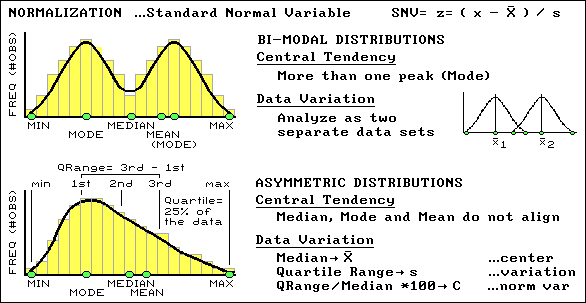
An alternative approach uses central tendency information to standardize a data set.
The standard normal variable (SNV) adjusts each measurement in a data set by
determining how different it is from the mean (what you would typically expect) as a
percent of the standard deviation (typical variation in the data). An adjusted SNV of 0
indicates a measurement that is as typical as it can get (exactly the same as the mean).
An SNV of -100 indicates an unusually low measurement (one Stdev below the mean), while a
SNV of +100 indicates an unusually high measurement (one Stdev above the mean). All other
SNVs indicate how typical the measurement is as a percentage of the standard deviation.
A SNV might be an unfamiliar way of looking at data, but it’s an extremely useful
normalization technique for comparison among data sets (such as soybean yield one year and
corn the next). Another "got’cha" in characterizing data involves non-normal
distributions. In these cases the histograms of the data do not conform to the
symmetrical bell-shaped curve. Sometimes the data can be bi-modal with two distinct peaks,
which often can be remedied by simply analyzing the measurements as two separate sets of
"normal" data. Asymmetrical distributions are a bit trickier as they tend
to be "skewed" to one side that necessitates the use of entirely different
central tendency metrics. In one approach, the median is used in place of the mean for
estimating the center, and a new metric, the quartile range, is substituted for the
standard deviation in estimating the variation (see figure). At this point your patience
with this little "stat refresher" is likely strained and you would like to just
"keep it simple stupid (KISS)." See the few "die-hards" of you online
for more details.